
<p>革命不是请客吃饭,不是做文章,不是绘画绣花,不能那样雅致,那样从容不迫,文质彬彬,那样温良恭俭让。革命是暴动,是一个阶级推翻一个阶级的暴烈的行动。</p>
<br/>
<p>《湖南农民运动考察报告》(一九二七年三月),《毛泽东选集》第一卷第一八页</p>机器学习
机器学习概述
学习系统的基本要求
- 具有适当的学习环境:学习系统进行学习时所必需的信息来源。
- 具备一定的学习能力:学习系统通过与环境反复多次相互作用,逐步学到有关知识,并且要使系统在学习过程中通过时间检验、评价所学知识的正确性
- 能用所学知识解决问题:学习系统能够把学到的信息用于对未来的估计、分类、决策和控制。
- 提高系统的性能:提高系统性能时学习系统的根本目的,通过学习,系统随之增长只是,提高解决问题的能力,使之能够完成原来不能完成的人物,或者比原来做的更好。
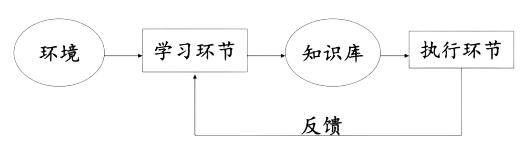
学习系统的基本模型
学习系统的四部分: - 环境 - 知识库 - 学习环节 - 执行环节
决策树学习
基本决策树ID3算法
- 大多数决策树学习算法是一种核心算法的变体
- 采用自顶向下的贪婪搜索便利可能的决策树空间
- ID3算法是这种算法的代表
ID3思想
- 自顶向下构造决策树
- 使用统计测试来确定每个实例属性单独分类训练样例的能力
- 从哪一个属性将在树的根节点开始
ID3过程
- 分类能力最好的属性被选作树的根节点
- 根节点的每个可能值产生分支
- 训练样例排列到适当的分支
- 重复上面的过程
ID3算法是一种自顶向下增长树的贪婪算法,在每个节点选取能最好分类阳历的属性。继续这个过程直到这个树能完美分类训练样例,或所有的属性已经被使用过。
那么,在决策树生成过程中,一什么样的顺序来选区实例的属性进行扩展,如何选择最高信息增益的属性为最好属性便是最重要的问题:
ID3算法-最佳分类属性
设给定正负实例的集合S,构成训练窗口。ID3算法视S为一个离散信息系统,并且用信息熵标识该系统的信息量。当决策有K个不同的输出时,S的熵为:
其中表示第类输出所占训练窗口中总的输出量的比例
- 为了检测属性作嗯药性,通过属性的信息增益Gain来评估其重要性。对于属性A,假设其值域为(v1,v2,…,vn)则训练实例S中属性A的Gain可以的定义为:
- Si表示S中属性A的值为Vi的子集;|Si|表示集合的势。
最佳分类举例
| 天气 | 温度 | 湿度 | 风速 | 活动 |
|---|---|---|---|---|
| 晴 | 炎热 | 高 | 弱 | NO |
| 晴 | 炎热 | 高 | 强 | NO |
| 阴 | 炎热 | 高 | 弱 | Yes |
| 雨 | 适中 | 高 | 弱 | Yes |
| 雨 | 寒冷 | 正常 | 弱 | Yes |
| 雨 | 寒冷 | 正常 | 强 | No |
| 雨 | 寒冷 | 正常 | 弱 | Yes |
<math xmlns="http://www.w3.org/1998/Math/MathML" display="block"><mi>E</mi><mi>n</mi><mi>t</mi><mi>r</mi><mi>o</mi><mi>p</mi><mi>y</mi><mo stretchy="false">(</mo><mi>S</mi><mo stretchy="false">)</mo><mo>=</mo><mi>E</mi><mi>n</mi><mi>t</mi><mi>r</mi><mi>o</mi><mi>p</mi><mi>y</mi><mo stretchy="false">[</mo><mn>4</mn><mo>+</mo><mo>,</mo><mn>3</mn><mo>−</mo><mo stretchy="false">]</mo><mo>=</mo><mo>−</mo><mfrac><mn>4</mn><mn>7</mn></mfrac><mi>l</mi><mi>o</mi><msub><mi>g</mi><mn>2</mn></msub><mfrac><mn>4</mn><mn>7</mn></mfrac><mo>−</mo><mfrac><mn>3</mn><mn>7</mn></mfrac><mi>l</mi><mi>o</mi><msub><mi>g</mi><mn>2</mn></msub><mfrac><mn>3</mn><mn>4</mn></mfrac></math>